Microsoft Search – översikt
Microsoft Azure Search är en ny tjänst i Microsofts utbud av moln-tjänster. Som utvecklare och lösningsarkitekt har jag under många år varit delaktig i att designa och utveckla system. Långt ifrån alla lösningar har blivit optimala vad gäller just sök-funktionaliteten och inte sällan just pga. tekniska begränsningar. Att implementera en bred sökning innebär ofta alltför stora Joins, trixande med temp-tabeller, inline-SQL i lagrade procedurer, denormalisering för redundans etc., utan att sök-lösningen ändå blir optimal. Microsoft SQL Server fulltext-index har tyvärr inte heller alltid levt upp till förväntningarna när stora datamängder ska hanteras. Även om det teoretiskt funnits tillräckliga förutsättningar för att implementera en optimal sök-lösning har det i praktiken ändå inte alltid gått att realisera då investeringsvilja och ekonomi hos kunder satt begränsningar. Sammantaget kan jag konstatera att svarstiderna i aktuella lösningar sällan blivit tillräckligt bra, inte minst i jämförelse med vad användare har vant sig med när de använder sökmotorer som Google och Bing. Tunga sökningar kan ju även ha en negativ inverkan på övriga svarstider i ett system. Därför är Microsoft Azure Search en välkommen tjänst som ger oss nya och förbättrade möjligheter att tackla de uppgifter vi har att lösa kring sökfunktionalitet i allmänhet.
En Microsoft Azure Search tjänst är otroligt smidig att sätta upp i Azure-portalen (https://portal.azure.com). Redan på den kostnadsfria nivån får man en utmärkt möjlighet att snabbt komma igång med att utvärdera och testa Azure Search.
Följande nivåer på tjänst kan väljas:
| Kostnadsfri | Standard | |
| Lagring | 50 MB | 25 GB / enhet |
| Frågor per sekund | n/a | 15 /enhet |
| Antal dokument | 10 000 dokumentMax 3 index | 15 miljoner/enhetMax 50 index |
| Skalbarhet | n/a | Max 36 enheter |
| Pris/timme | Kostnadsfri | 2.25/h -> 1679 kr/mån |
| Dataöverföring | Standardtaxa | Standardtaxa |
Tjänsten är så flexibelt utformad att man kan skala upp och ner för att möta varierande belastning på ett kostnadseffektivt sätt. För att få bättre prestanda kan man kombinera enheter och få fler frågor per sekund eller ett större antal dokument, eller bådadera. Enheterna kan även kombineras för att möjliggöra hög tillgänglighet eller snabbare dataintag.
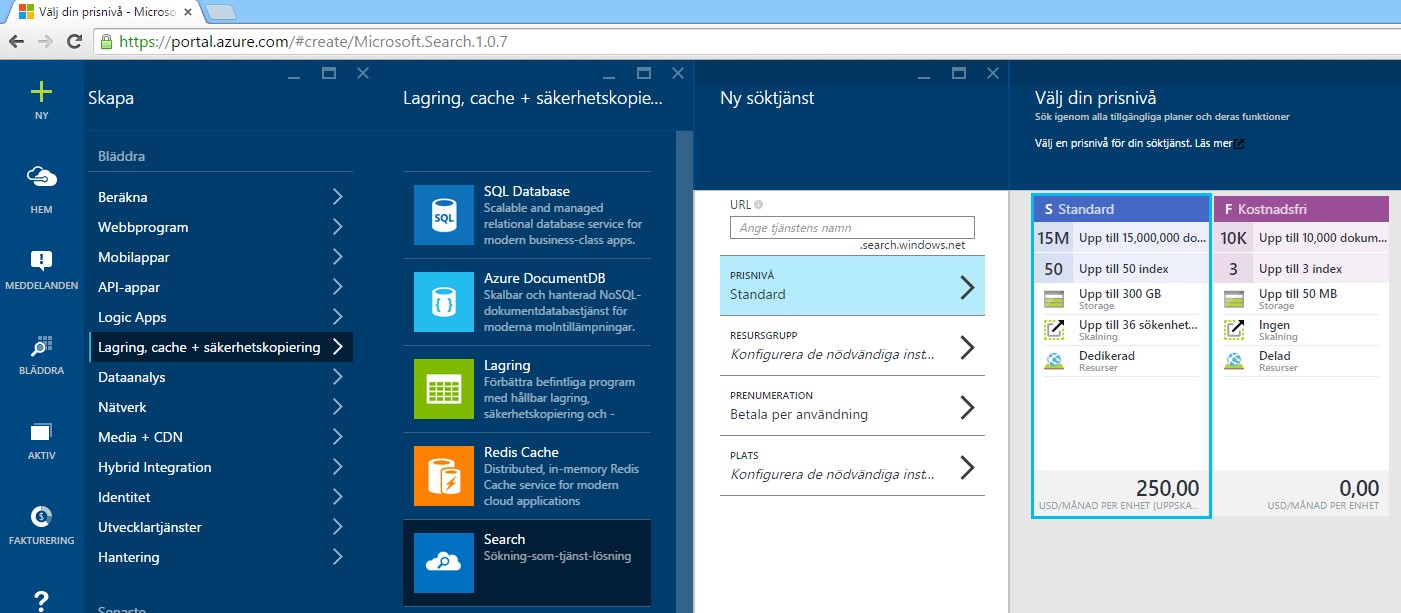 Figur 1 – Tjänsten skapas i Azure portalen
Figur 1 – Tjänsten skapas i Azure portalen
När tjänsten är skapad registrerar man sina index (alltså motsvarigheten till tabeller i sök-sammanhang), antingen via REST API, .NET SDK eller direkt i Azure Portalen.
Ett Azure Search-index är ett schemabaserat index där ingående fält definieras. Dessa fält har för utom ett namn och en datatyp även ett antal egenskaper som styr sökfunktionaliteten. Dessa egenskaper beskrivs nedan:
| Filterable | Anger om filter uttryck kan användas för fältet |
| Facetable | Anger om automatisk fasettdata ska skapas vid sökning. Fasettdata är grupperingsinformation om hur många distinkta förekomster som finns i sökresultatet. |
| Retrievable | Anger om fältets data ska gå att få i retur vid sökning |
| Searchable | Anger om fältets data ska gå att söka i |
| Key | Anger om fältet är primärnyckel i indexet |
| Sortable | Anger om sökresultatet ska kunna sorteras på fältets data |
| Suggestions | Anger om sök-förslag ska hämtas från fältets data |
Microsoft Azure Search har även stöd för bedömningsprofiler av data vilket med fördel används för att optimera sökresultatet.
Synkronisering av data
Via REST API eller .NET SDK kan man implementera sin egen lösning för att hantera push- eller pull synkronisering mellan Azure Search Index och sitt domän data. En push uppdatering innebär att data överförs synkroniserat med en förändring av domändata medan en pull uppdatering inte sker synkroniserat och ofta med viss latency. Fördelen med att använda .NET SDK är att det erbjuder generiska metoder för hantering av index.
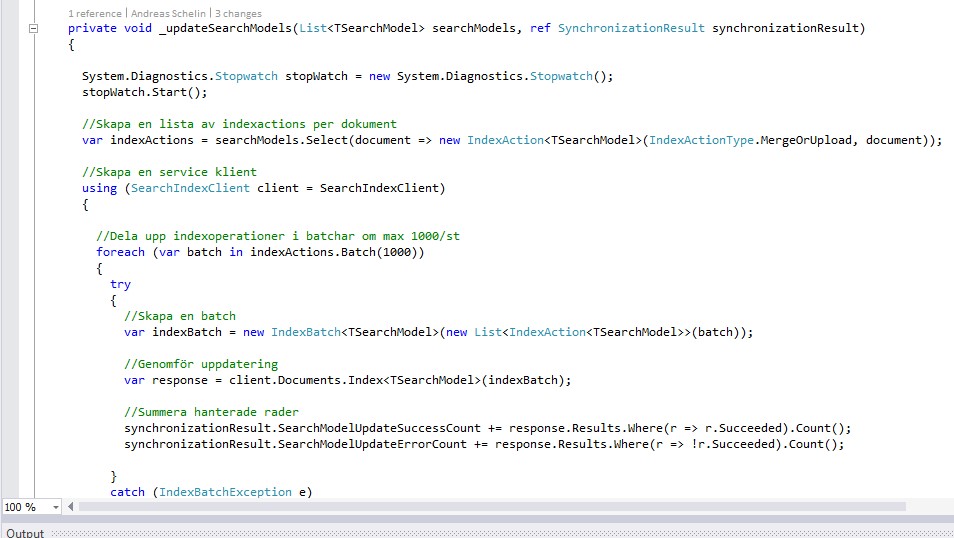
Figur 2 – Exempel på synkronisering av data via SDK
Om Microsoft Azure SQL används finns det färdigt stöd för indexeringstjänser direkt mellan Azure Search och Azure SQL för ”push”-uppdatering.
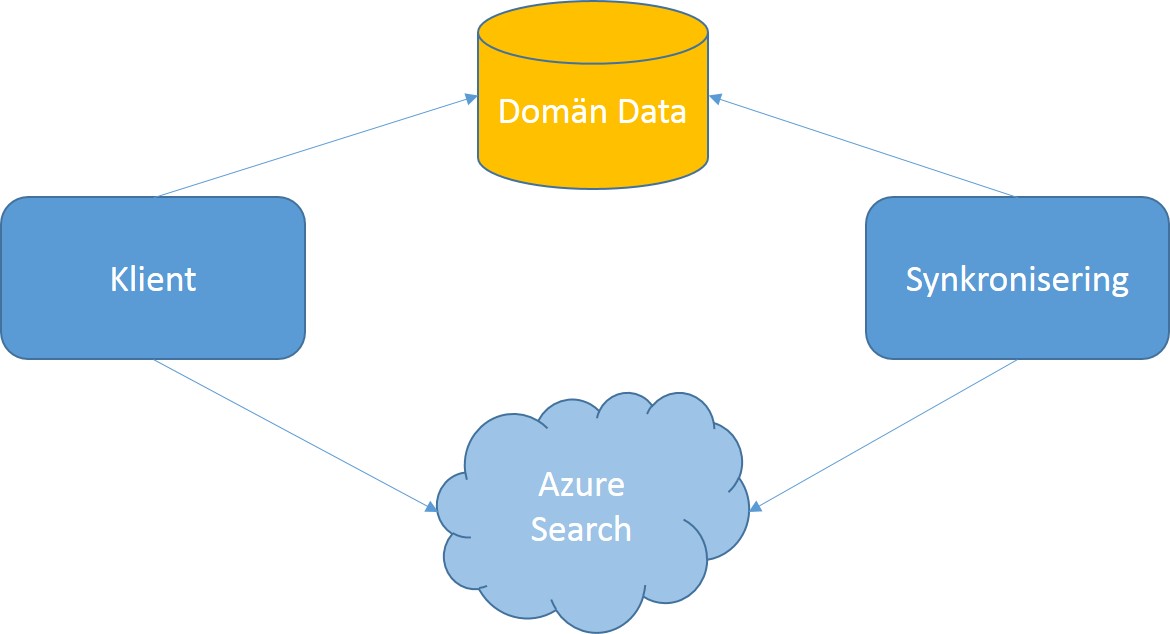
Figur 3 – Azure Search är ett komplement till domänapplikationen
Om man använder Microsoft SQL Server 2008 eller senare är det enkelt att implementera synkronisering av indexdata genom att använda s k ”change tracking” i SQL Server. Genom att slå på ”change tracking” för databasen och de tabeller som är underlag för indexdata blir det väldigt enkelt att hämta förändrad data via SQL funktionen CHANGETABLE(). Med denna teknik i botten går det lätt att implementera en lösning för ”pull”-uppdatering av indexdata. En fördel med detta tillvägagångssätt är att domän-databasen inte påverkas eftersom ”change tracking”-funktionaliteten är en del av Microsoft SQL Server. Med andra ord kan synkning mellan Microsoft SQL Server och Microsoft Azure Search implementeras med minimal påverkan på befintlig lösning.
Sökning
Sökningar mot Microsoft Azure Search görs också via REST API eller .NET SDK. Grundprincipen är att skicka med en s.k. fulltext frågeuttryck där man även kan specificera wildcard. I fråge-anropet går det även att skicka med ett filteruttryck för de fält som i indexet har angivits som filtrerbara. Man kan också tala om hur man vill ha resultatet sorterat genom att ange ett eller flera fält vilka markeras som ”sorterbara” i stigande eller fallande sortering. Om resultatet ska innehålla Facets så skickar man även med vilka fält som man vill få Facet-resultat för. Det finns även stöd för Take och Skip för att implementera s.k. ”Paging” vilket innebär att resultatet delas upp i sidor.
De viktigaste parametrarna är följande:
| search | Sökuttryck. Detta fält är valfritt och sätts automatiskt till ”*” om det utelämnas. |
| searchMode | any|all. Detta fält är valfritt och sätts automatiskt till any om det utelämnas. Anger om något eller samtliga söktermer ska matchas. |
| skip | Antalet poster i sökresultatet som ska hoppas över. Värdet är valfritt. |
| top | Antalet poster i sökresultatet som ska hämtas. Värdet är valfritt med ett standardvärde på 50. |
| count | true|false. Anger om det samtliga poster i resultatet ska hämtas. Värdet är valfritt med ett standardvärde false. |
| orderBy | Kommaseparerad lista för angivande av sortering. Kan antingen innehålla fält eller anrop till funktionen geo.distance. Även asc /desc kan anges för varje fält. Fältet är valfritt och om det utelämnas är det från document match score som sortering görs i fallande ordning. |
| select | Kommaseparerad lista över vilka fält som ska inkluderas i resultatet. Värdet är valfritt och om inget värde anges inkluderas samtliga fält som märks ”retrievable”. |
| facet | Kommaseparerad värde-par lista över facet-instruktioner. |
| filter | Ett strukturerad OData uttryck för filtreringsuttryck. Fältet är valfritt. Logiska uttryck and, or och not kan användas tillsammans med uttryck för jämförelse såsom eq, ne, gt, lt, ge, le. |
(för mer information se https://msdn.microsoft.com/en-us/library/azure/dn798927.aspx)
Azure Search Service erbjuder även funktionalitet för att hantera ”suggestions” dvs. förslag på matchande söksträngar precis som vi är vana med att kunna använda i dagens sökmotorer. När användaren förändrar sökuttrycket kan man genom ett bakgrunds-trådat anrop till tjänsten anropa metoden ”Suggest” för att hämta förslag på sökuttryck och på så sätt underhålla en s.k. ”auto-complete” lista.
Facets gör att vi enkelt kan visa sökresultatet grupperat i alternativa filteruttryck, t.ex. vilka varugrupper, märken och leverantörer som sökresultatet innehåller samt antalet förekomster inom respektive grupp.
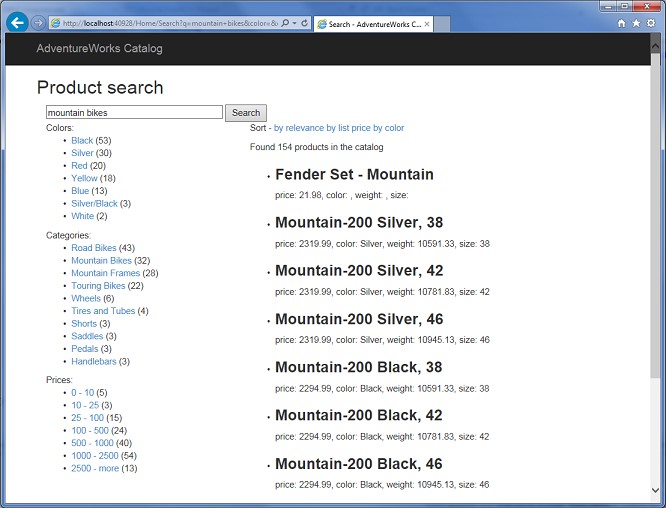
Figur 4 – Exempel på sökresultat med facet
När användaren hittat det resultat som eftersöktes hämtas domän-data på vanligt vis via applikationens egen tjänst mot domänens data eller någon annan dokumentbaserad tjänst. På detta sätt har vi avlastat vårt eget system från de ofta tunga och breda sökningar som sker i ett domänsystem samtidigt som vi fått en mycket rikare, snabbare och mer konventionell upplevelse.
Avslutning och slutsatser
Den teknik som Microsoft Azure Search utnyttjar för lagring och sökning är helt abstraherad från de API:er som exponeras. Även om ryktet stämmer, att det skulle vara Elastic Search i botten som används, så saknar detta i så fall ändå praktisk betydelse. Moln-tjänster har ju den stora fördelen att man inte ska behöva bry sig om bakomliggande infrastrukturen. Att använda Microsoft Azure Search behöver alltså inte vara ett stort strategiskt beslut eftersom ingen hänsyn behöver tas till bakomliggande hård- eller mjukvara. Och eftersom trenden de sista tio åren inneburit en övergång till tjänstebaserad arkitektur är det bara ytterligare en tjänst i floran som tillkommer. Vi har i våra system sett möjlighet att kombinera existerande lösningar som körs i kundens egen driftmiljö med moln-tjänster som MS Azure Search. Detta ger kunden en bra möjlighet att successivt, på ett kontrollerat och säkert sätt och baserat på faktisk nytta och värde, flytta sina lösningar in i molnet.
Microsoft Azure Search bör inte användas för att lagra dokument, även om det är fullt möjligt. Vår erfarenhet pekar på att tjänsten används optimalt om den utnyttjas för det den är designad för, nämligen sökning. Dokument bör således lagras för sig i t.ex. Azure Document DB.
Fördelen med att använda Microsoft Azure Search är att man kan leverera den sökupplevelse som användare idag förväntar sig, både i sättet hur man söker men även vad gäller svarstider och presentation av resultatet.
Om man dessutom beaktar den kraftfulla funktionaliteten som Microsoft Azure Search ger tillsammans med en relativt liten tidsåtgång för implementation samt att ingen ytterligare investering i hård- eller mjukvara behöver göras, måste slutsatsen vara att Microsoft Azure Search är ett alternativ alla borde överväga.
– Andreas Schelin, lösningsarkitekt på Softarc
För mer information om MS Azure Search samt exempel se http://azure.microsoft.com/sv-se/services/search/
Se även http://azure.microsoft.com/sv-se/services/documentdb/ för Azure Document DB och http://azure.microsoft.com/sv-se/services/sql-database/ för Azure SQL Database
Senaste kommentarer